코로나 이후 처음으로 한국에서 여러 분들을 만났다.
이전에는 제가 아는 많은 분들이 한국 사회의 발전을 의심하는 망국론을 펼쳤다. 버젼도 다양하다. FTA 망국론, IMF 망국론, 신자유주의 망국론, 쌀개방 망국론, 스크린 쿼터제 폐지 (=외세 장악) 망국론, 지역갈등 망국론, 노사 갈등 망국론, 헬조선, 개천룡이 더 이상 나오지 않는 사회, 지속되는 경제 위기, 사회적 신뢰 부재 망국론, 불평등 폭발 망국론, 빨갱이 득세 망국론 등등등.
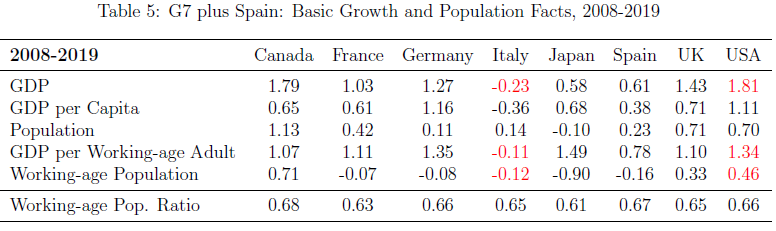
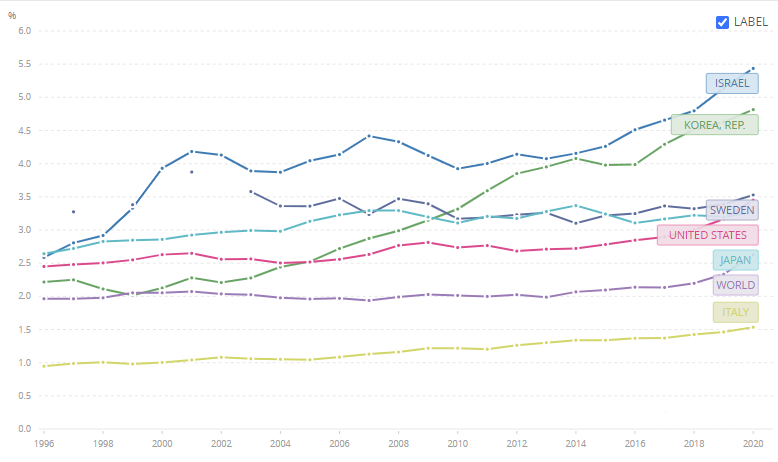
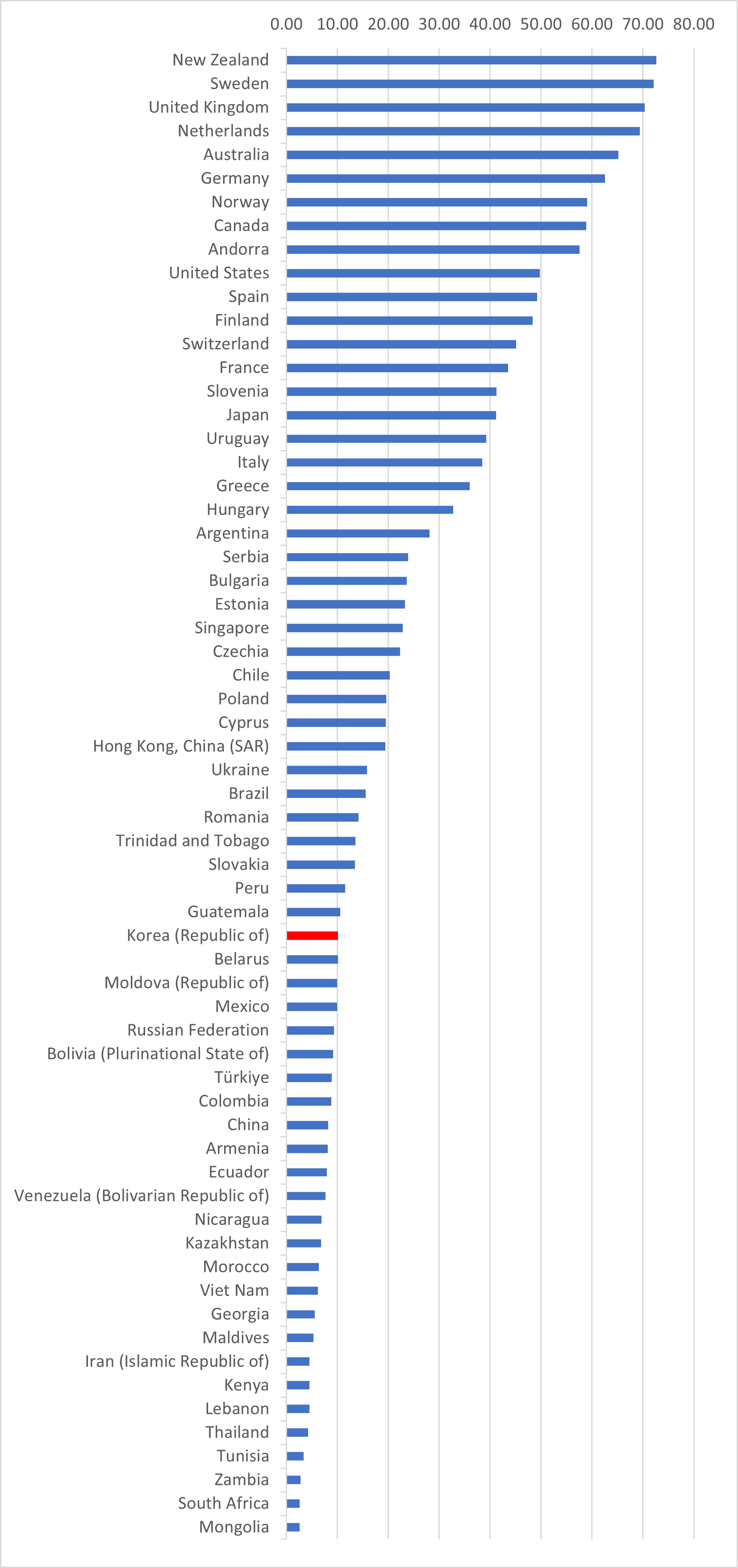
유학 초기에 같이 공부하던 몇 분은 한국은 남미처럼 위기를 반복할 것이기에, 한국을 위한 대책을 세울려면 유럽을 공부할 것이 아니라 남미의 역사를 공부해야 한다고도 했다. 하지만 한국은 21세기에 지속발전했고, 선진국이 되었다. 계산해보니 한국의 장기 성장률이 OECD 톱2에 속하더라.
한국을 방문할 때마다 한국이 다른 국가에 비해서 견고한 성장세를 유지하고 있고 선진국의 반열에 오르고 있다는 점을 설파해야 했었다. 그런데 이 번 방문에서 만난 많은 분들이 한국이 그 동안 발전해서 선진국이 되었다는 것은 인정하더라.
1990년대에는 일본에 가면 음식 값이 너무 비싼데 양은 적어서 배가 고프다는 감상이 많았는데, 이제는 일본 물가가 한국 물가보다 싸게 느껴진다더라. 코로나 시국에 한국의 방역이 상찬을 받은 것, K-Pop과 K-드라마의 성공도 이런 분위기 변화에 한 몫 했을 것이다.
예전과 달라진 점은, 더 이상 망국론을 피지 않는게 아니라, 지금까지는 성장했지만, 이제는 운이 다해서, 앞으로 꺾이게 될 것이라는 망국론을 피더라. 윤석열 망국론, 인구감소 망국론, 좌파득세 망국론 등 몇 개 버젼이 있지만 예상되는 추세는 모두가 일치했다. 앞으로는 내리막길이라는거.
이런 주장을 들으면, 한국의 발전을 설명하는 변수와 이론이 없는데, 한국이 앞으로 지속 발전할지 아니면 하향국면에 들어갈지 어떻게 아는가라는 의문이 생긴다. 지난 발전의 요인을 알아야 그 요인이 소멸했는지 아직 굳건한지 알고, 그에 기반해서 미래를 예측하지, 지난 발전의 요인을 모르는데 미래를 어떻게 예측하는가? 대부분의 한국 망국론은 발전과 쇠퇴를 같은 관점에서 설명하지 않고, 당시의 사회적 분위기를 반영하는 몇 개 애드혹 변수를 그 근거로 한다. 느낌적느낌 망국론이다.
몇 년 전에 출간된 <추월의 시대>라는 책이 있다. 시대적 변화를 잘 반영한 제목이라 기대를 품고 읽었던 책이다. 재미있고 잘 쓰긴 했는데, 왜 한국이 추격에서 추월로 바뀌게 되었는지 그 동력이 무엇인지 논하지 않더라.
사회학에서는 여러 분들이 온갖 문제점들은 잘 분석했지만, 왜 한국은 다른 국가보다 더 빠르게 21세기에 성장했는지 말하지 않는다. 몇 년 전 뉴욕에서 열린 학회에서 한국사회학회 회장님이 한국 사회의 위협 요인으로 사회 갈등 문제를 발표한 적이 있다. 그 때 들었던 의문은 갈등이 그렇게 나쁜거고, 한국에서 사회 갈등이 그렇게 문제라면, 도대체 왜 한국은 발전하는가였다.
(저를 포함하여) 인정하고 싶지 않은 분들이 많겠지만, 온갖 망국론을 뚫고 지금까지 살아남은 논리는 신자유주의 개혁론이다. 경쟁이 없던 독과점, 정경유착 경제가 90년대 신자유주의적 개혁을 거쳐 경쟁과 혁신 위주의 경제로 바뀐 결과 한국은 발전했다는거다. 이 논리에 따르면 지금이 고점이라는 근거가 없다. 사람을 갈아넣고 경쟁으로 내모는 시스템은 심리적으로는 불만스러워도 발전은 지속된다. 윤석열 정부에서 이러한 시스템을 바꿀리도 없고.
널리 전파된 적은 없지만, 나름 일관성이 있는 논리는 "상상의 선진국론"이다. 여러 국가의 장점만 따다가 상상의 선진국을 만들고, 그 선진국을 닮는 방향으로 지금까지 발전해왔는데, 이제 선진국이 되어서 더 이상 닮고자 하는 모범이 없으니, 지표를 잃고 표류하게 될 것이라는 전망이다. 카피캣의 극단적 모범사례가 한국이라는 진단이다. 이 논리의 문제는 왜 다른 카피캣은 한국처럼 발전하지 않았는지를 설명하지 못한다.
논리를 조금 비틀자면 망국발전론도 가능하다. 항상 불만을 가지고 문제를 발견해서 그걸 해결하려고 노력하다보니 발전하더라는거다. 항상 불행하지만, 발전은 지속되는 원리가 설명된다. 조금 포장하자면 갈등이 역동성을 부여해서 순작용을 하더라는거다. 안정된 행정조직에 정치사회적 역동성이 추가되어서 지속 발전이 가능했다는 것.
또 다른 논리로 인구정점론이 있다. 출산율이 하락하고 인구가 줄어들기 때문에 앞으로는 발전이 안된다는거다. 이 논리는 생산함수의 요소 투입론 아니겠는가. aKL에서 노동인 L이 투입되었는데 이제는 그게 어려워진다는 것. 하지만 한국은 요소 투입과 더불어 생산성이 꾸준히 늘었다는걸 잊으면 안된다. 출산율 하락이 1인당 생산성 하락으로 이어지는건 아니다. 일본도 고령인구의 증가로 1인당 GDP는 빠르게 증가하지 않았지만, 핵심노동인구의 생산성은 계속 증가했다는 보고도 있다. 게다가 비록 그 기울기가 가파르긴 하지만 인구 감소가 한국만 직면한 문제도 아니다.
또 뭐가 있나?
제가 답을 안다는건 아니다. 다만, 한국 사회과학계가 가져야할 가장 큰 의문점 중 하나가 한국이 발전한 이유가 아닌가 싶다. 21세기 한국이 겪은 가장 큰 사건이 바로 선진국 진입인데, 이를 설명하는 (좌파의) 사회과학적 이론이 부재하다.