뉴욕타임즈 기사: Pandemic Aid Programs Spur a Record Drop in Poverty.
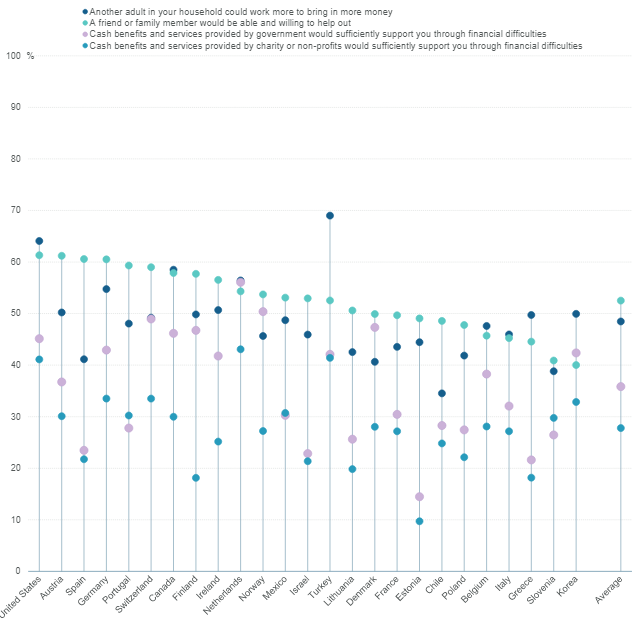
아래 그래프에서 보다시피 코로나 이후 미국에서 전연령대, 전인종, 전지역에서 빈곤율이 격감했다. 2018년 13.9%에서 2021년 추정 7.7%로 거의 절반으로 줄었다. 이유는 간단. 전국민 재난지원금을 대량으로 지급했고, 실업보험료를 인상하고 더 오랫동안 지급했고, 기존 빈곤 프로그램을 확대했기 때문.
미국은 코로나 위기에 천문학적인 금액을 국민지원에 사용하였다. 서울신문 칼럼에도 썼지만 GDP 대비로 봤을 때 한국의 5.7배에 달한다. 1인당 지원의 절대액이 5배를 넘는다는게 아니라, GDP 대비 비중에서 5배 넘으니까, 절대액으로 보면 10배가 넘는다. 뉴욕타임즈 기사를 읽어보면 지원규모가 얼마나 엄청났는지 감을 잡을 수 있다. 한 미혼모는 팬데믹으로 연봉 3500만원 일자리에서 실직이 되었는데, 실업보험, 재난지원금, 자녀들의 푸드스탬프 등으로 실직 상태에서 오히려 소득이 30% 이상 늘었다.

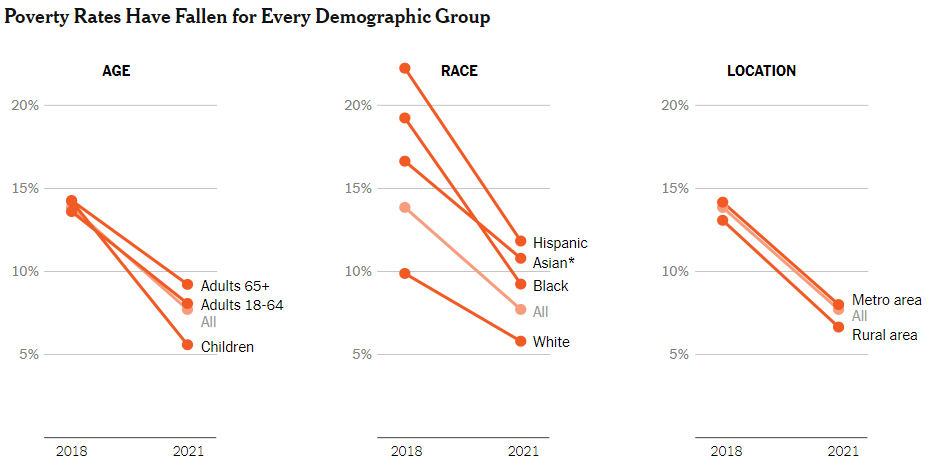
문재인 정부에서 80% 지급이니 100% 지급이니 하는 논란으로 몇 개월을 끄는 것은 한심하기 그지없었다. 80%든 100%든 규모를 더 키우는게 더 중요했으니까.
한국에서 재난지원금을 확대하고 빈곤 감소, 불평등 감소의 효과가 크게 나타났을 경우, 이에 기반해 사회보장 프로그램을 확대하고, 지속가능성을 높이기 위해 증세해야 한다는 분위기, 최소한 논쟁을 불러일으킬 수 있었지만, 안타깝게도 문재인 정부는 이 위기를 기회로 전환하는데 실패했다.
미국에서 코로나 기간 동안의 사회보장 정책 효과가 워낙 뛰어났기에, 이 정책을 규모는 축소하더라도 연장해야 한다는 목소리가 높다. 세전 불평등을 줄이는 것은 어렵지만, 세후 빈곤율을 줄이는 것은 정책적으로 충분히 가능하다. 한국에서도 작년 재난지원금 지급 직후 가계동향조사 결과에서는 불평등과 빈곤이 감소했었다.
원리는 간단하다. 빈곤과 불평등은 모두 소득의 절대액에 더 민감하다. 국가에서 세금을 소득에 비례해서 많이 걷고, 이렇게 걷은 세금을 동일한 절대액으로 배분하면 빈곤과 불평등이 줄어든다. 빈곤과 불평등을 줄이는 것은 정책의 질이 아니라 양이다. 빈곤과 불평등을 줄이기 위해서 세금을 얼마나 누진적이고 진보적으로 걷는지보다, 세금의 총액이 훨씬 더 중요하고, 정책적으로 하위계층을 얼마나 잘 타겟으로 하는 것보다 하위계층에게 돌아가는 절대액을 늘리는 것이 훨씬 더 중요하다.
정치적 경제적으로 감당 가능한 범위 내에서 소득 비례 세금과 배분 절대액을 기회가 있을 때마다 최대한으로 높이는 것이 최선의 사회보장 정책이다. 이것이 팬데믹 기간 중에 빈곤이 줄어든 미국에서 배워야할 교훈이다.
Ps. 위 그래프에서 보다시피 팬데믹 사회보장 효과로 빈곤이 격감하기 전에도 최근 7~8년간 미국에서 빈곤은 꾸준히 줄어들었다. 트럼프 4년 동안 빈곤이 상당히 감소했다. NYT 기사에서는 언급하지 않았지만, 특히 흑인의 빈곤이 트럼프 기간 동안 많이 줄었다. 경제성장은 빈자들에게 도움이 된다.
Pps. 미국의 돈풀기는 자산가치를 높여서 자산불평등을 심화시켰다. 한편으로는 불평등이 심화되었지만, 다른 한편으로는 빈곤이 줄었다. 빈곤 축소와 자산불평등 축소를 한꺼번에 달성하기 어려울 때는 전자에 정책의 초점을 두어야 하는거 아닌지. 자산불평등에 초점을 두면 하위계층은 정책적으로 소외되기 쉽다.